標準偏差と標準誤差: 定義、違い、使用例など
UB3/statistics/basics/sd_se
このページの最終更新日: 2026/04/09- 標準偏差 SD
- 不偏標準偏差
- 標本標準偏差
- 標準誤差 SE
- サンプル数を増やすと、SD と SE の違いがはっきり見えてくる
広告
標準偏差 Standard deviation, SD
不偏標準偏差 standard deviation (SD or σ) とは、不偏分散 unbiased variance (しばしば シグマの2乗 σ2 で表される) の平方根であり、以下の式で表される (1)。ただし、X は全てのデータの平均値、xi はそれぞれのデータの数字、n は全てのデータの数である。
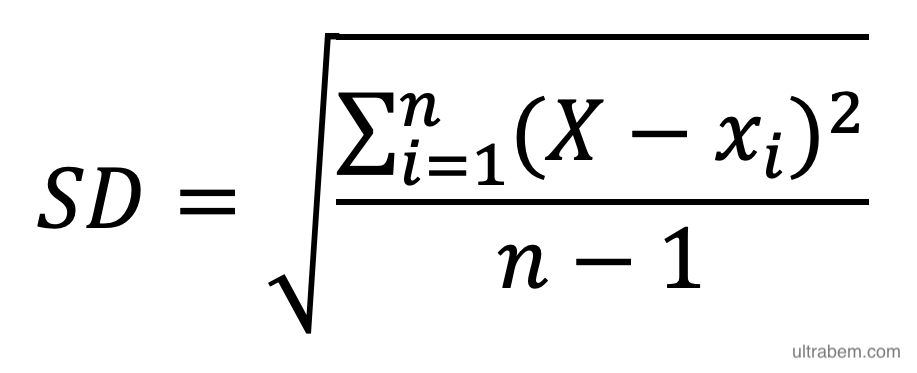
この式の意味するところは以下の通り。
- 平均値から個々のデータの値を引く。
- これを全部足し合わせたいのだが、値がプラスの場合とマイナスの場合があるので、それぞれを二乗してから足し合わせる。
- それを自由度 (データの個数 - 1) で割る。
したがって、
なお、標本集団のデータから計算されるこのバラツキは、
この SD の特徴から、逆に異常値について考えることもできる (1)。つまり、平均値 ± 2SD の間に 95% の値が含まれるわけだから、たとえばあるデータの値が平均値 ± 2 SD 以上であったら、その値は少なくとも全体の 5% という珍しい値であることになる。
ただし、不偏標準偏差がデータのバラツキを示す指標として適切なのは、データの分布が正規分布に近いときのみである (3)。
SD は、Excel の関数 =stdev で簡単に計算できる。stdev は、分母に n ではなく n - 1 を置いた不偏標準偏差である。n を使う場合は =stdevp を用いる。
広告
標準誤差 Standard error
標準誤差 standard error は、不偏標準偏差をサンプル数の平方根で割ったものであり、
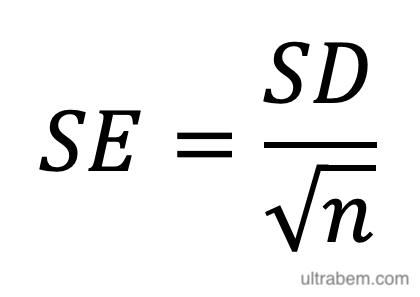
で与えられる。この値の意味するところは、以下のように説明できる。
- 母集団からある数の標本を選び、その平均値を計算する。この平均値を標本平均と呼ぶ。
- この操作を何回も繰り返すと、当然標本平均にもバラツキが生じる。
- 標本平均の標準偏差を標準誤差 standard error of means (SEM) という。
標準誤差はさまざまな統計量に対して定義できるが、単に標準誤差と言った場合はこの「標本平均の標準誤差」のことを指す。このことをちゃんと表現したい場合は、英語ならば SE ではなく SEM を用いる方が良い。
標本平均の不偏標準偏差から上の式を導く仮定はややこしいので、いずれ別のページでまとめることにする。文献 4 にその過程が示されてい
サンプル数を増やすと、SD と SE の違いがはっきり見えてくる
ここでは、
- 不偏標準偏差 SD は母集団のバラツキを表す
- 標準誤差 SE は、母集団の平均とのずれを表す
というこのページの主要な結論を、MATLAB を使ったプログラミングで確認する。
生物学実験では、原則として母集団の平均値、分散、不偏標準偏差はわからないので、標本についてデータを得て、そこから母集団の値を推測するという手順を踏んでいる。
サンプル数 n を増やしていくと、それは母集団の標本数に次第に近づいてゆく。このとき、標本集団の平均値 m は、次第に母集団の平均値 (真の平均値) M に近づいていくだろう。分散は、母集団の分散に近づいていく。分散の平方根である不偏標準偏差も、母集団の標準偏差に近づいていく。
一方、標準誤差 SE は何に近づいていくだろうか? これは 0 に近づいていくのだが、以下のように複数の説明が可能である。実際には、どれも同じことを言っている。
- SE は SD をサンプル数 n の平方根で割ったものなので、n が大きくなると 0 に近づいてゆく。すなわち、母集団が非常に大きいと仮定すると、分母は限りなく大きくなるが、分子は母集団の標準偏差付近で足踏みしていることになる。母集団の正規分布を仮定する限り、不偏標準偏差は有限のそれなりの値である。
- 母集団から標本をとってその平均値(標本平均)を計算するとき、標本数 n が大きくなると、標本平均は 「母集団と同じ平均値をもち、標準偏差 SE の正規分布」に近づく。これを中心極限定理 central limit theorem という。n が大きくなると、標本平均は母集団の平均の近くに集まる。
標準誤差は、母集団の平均が収まる範囲を推定するもの であり(1)、母集団、n がともに極めて大きい場合、両者の平均値はほぼ一致して、標準誤差はほぼ 0 になる。
寿命の平均が 85 歳、標準偏差が 10、50,000,000 人から成る母集団を考える。ここから n 人から成る標本集団を選んで、寿命の平均値、SD, SE を算出する。 n を 2 から 1000 まで変化させたとき、これらの値はどのように変化するだろうか?
結果は下の図の通り。
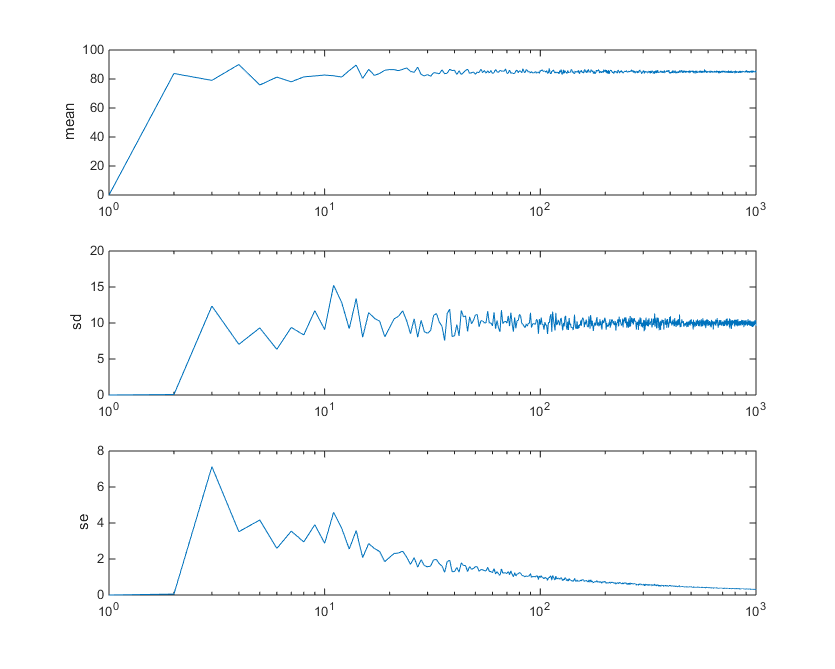
上から平均値、SD、SE の変化である。横軸は n の対数で、2 から 1000 までを検討した。標本集団の SD は、n が大きくなると
- 標本集団の SD は母集団のバラツキ(標準偏差)の推定値である。
- しかし、標本集団のデータの質が低い場合(実験的要因によってばらついている場合、n が不十分な場合など)には、当然そこから推定される母集団のバラツキも大きくなる。
- 結果として、SD が標本集団のバラツキのように見えてしまうこともある。または、SD は母集団のバラツキと、n が少ないことなどによる評価のバラツキの和になるとも言って良いか。
一方、SE は単調に減少し、n = 1000 でもまだ減少傾向を保っていることがわかる。平均値も 85 に収束しており、n が増えるほど精度の高い推定ができていると考えられる。
広告
References
Cumming et al. 2007a. Error bars in experimental biology. J Cell Biol 177, 7-11.- 明治大学 数値情報論 2010. http://www.kisc.meiji.ac.jp/~nino/2010/index.html
- 標準偏差と標準誤差:どちらを使うべきか? Web pdf.
- 統計学入門. Web.
- 池田 2013. 統計検定を理解せずに使っている人のために I. 化学と生物 51, 318-325.
コメント欄
サーバー移転のため、コメント欄は一時閉鎖中です。サイドバーから「管理人への質問」へどうぞ。