R cor.test() 関数: オプションと実例
UB3/informatics/r/cor_test
このページの最終更新日: 2026/07/11広告
cor() 関数
cor() 関数は相関係数を算出するのみであるが、cor.test() 関数では相関しているかどうかの検定も同時に行われ、P 値も算出される。実際に cor() 関数を使うことはほとんど無いと思われるが、一応解説しておく。
シンプルな使い方は以下の通り。x と y がともに vector のとき、両者の correlation を計算する。x と y が行列の場合は、それぞれの列に対して covariances または correlations を計算する。
use |
use = "everything" はデフォルトで、指定しなければ自動的に everything になる、つまり全てのデータが使われる。データに欠損値 NA がなければ問題ないが、NA があると結果も NA になってしまう。 use の引数には、everything および complete.obs のほかに、NA が入っているとエラーになる all.obs など 5 つがある。文献 2 を参照のこと。 |
method |
pearson の部分を kendall または spearman にすることで、ノンパラメトリックな分析も可能。method = "pearson" としても動いた。 |
cor.test() 関数
Pearson's product momemt correlation coefficient, Kendall's tau または Spearman's rho を使って、相関が有意であるかどうかを検定する。
各種オプションは以下の通り (5)。網羅しているわけではないので、詳細は RDocumentation (Ref. 5) を参照のこと。
method |
cor 関数と同様に、pearson, kendall または spearman を指定する。method = "pearson" としても動いた。 |
exact |
NULL, TRUE および FALSE を指定することができ、NULL がデフォルトである。 kendall または spearman で計算されるのは順位相関係数である。つまり、これらはデータを順番に並べて検定する方法であり、同値 (tie values) があるときに順位がつけられないという問題が生じる。この場合、正確な P 値が計算されなくなる。 exact については、以下のような説明がみつかった (5)。 "For Kendall's test, by default (if exact is NULL), an exact p-value is computed if there are less than 50 paired samples containing finite values and there are no ties. Otherwise, the test statistic is the estimate scaled to zero mean and unit variance, and is approximately normally distributed." "For Spearman's test, p-values are computed using algorithm AS 89 for n < 1290 and exact = TRUE, otherwise via the asymptotic t approximation. Note that these are ‘exact’ for n < 10, and use an Edgeworth series approximation for larger sample sizes (the cutoff has been changed from the original paper)." |
cor.test のアウトプットは、8 個の項目をもつリストである。これをオブジェクトに保存し、データを取り出すのも、実際の解析でよく使われる手順である。例えば、相関係数は estimate という名前で保存されているので、以下のように取り出すことができる。
A$estimate
アウトプットの内容を表にしておく。いずれも $ を使って同様に取り出すことができる。
p.value |
相関検定の p 値 |
estimate |
相関係数。Peason, Spearman などの method によって変わる。 |
広告
「あとがき」で当サイトを参考にしたと書いてくれているラノベです。Kindle Unlimited で読めました。ストーリーと文章が良く、面白かったです。
実際の手順
基本的な手順は次の通り。
- 散布図を作り、大体の傾向をつかむ。最終的にこの散布図のデータがどこにも使われなかったとしても、データの理解に重要なステップである。
- 相関がありそうだったら、まず正規性をチェック。
- その結果に応じて、パラメトリックまたはノンパラメトリックな検定を cor.test() 関数を用いて行う。
散布図の作成
R 組み込みデータセット swiss を使ってみる。swiss はスイスの各地方における出生率と、さまざまな社会要因のデータである。
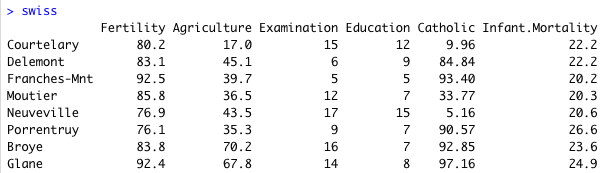
最も関係していそうな Examination と Education に相関があるかどうかを調べてみよう。
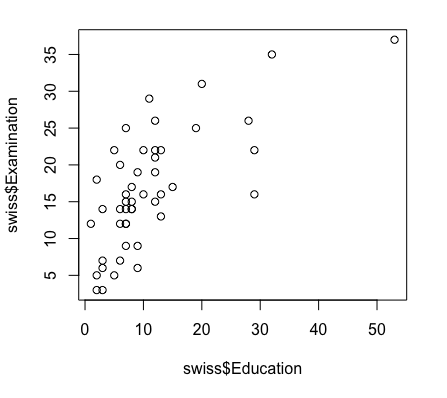
右肩上がりのプロットになり、正の相関があるように見える。そこで、次のステップへ進む。
なお、この散布図は一番シンプルなものを plot 関数 で作っているが、詳細が知りたい場合には以下のページを参照のこと。
正規性の検定
Shapiro-Wilk 検定とその結果を示す (参考: R を使った Shapiro-Wilk 検定)。
W = 0.7482, p-value = 1.312e-07
W = 0.96962, p-value = 0.2563
Shapiro-Wilk 検定の帰無仮説は「変数は正規分布に従う母集団からサンプリングされた」である。したがって、Education では帰無仮説が否定されてしまって、つまり正規分布には従わないことになる。一方、Examination では帰無仮説が否定できず、つまりこの変数は正規分布に従うことになる (参考: 仮説検定)。
実際にヒストグラムを書いてみると、Education は非常に skew した分布になっていることもわかる。
したがって、これらの相関をテストするには、ノンパラメトリックな手法を使わなければならない。
スピアマンの検定
ノンパラメトリックな相関分析には、Spearman と Kendall という 2 つのよく使われている方法があり、前者の方が一般的である。今回は Spearman の方法を使ってみる。
これでスピアマンの相関係数 0.6746038 が算出される。cor.test は、以下のようにスピアマンにすると P 値などは算出されるが、Cannot compute exact p-value with ties というエラーメッセージが出る。tie というのは「同じ数値」があるということで、Mann-Whitney U 検定でも同じエラーに遭遇することがある。
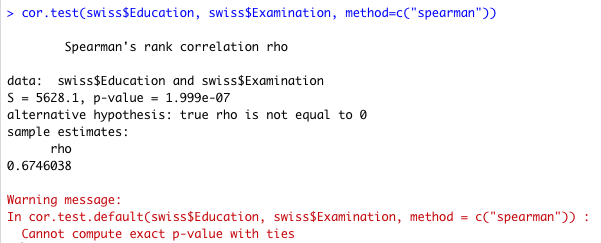
exact = FALSE というオプションをつけると、このエラーを回避できる。
ピアソンの検定
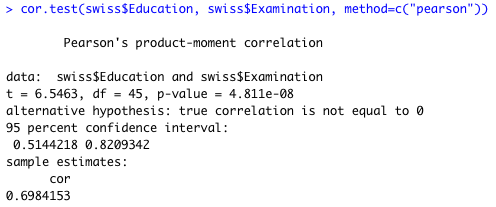
ピアソンの検定 のページでは、相関係数の定義や Excel を使った検定を紹介している。実例として、同じ swiss のデータセットを使っている。
Excel では t 値が 6.546262224、P 値が 4.8114E-08 と計算されるが、これが R でも同じ値であることを確認しておこう。
広告
References
- 兵庫研究大学 成田滋氏のページ. 直線的関連. Link.
- Untitled Note. データに NA がある時の相関係数. Link: Last access 2020/05/26.
- ひとつのファイルのデータの処理. Link: Last access 2020/07/15. cor.test の結果が、どのようなデータフレームとして保存されているかが解説されている。P 値のみを抽出するときに使った。
- 相関係数の有意性を確かめる方法について -相関係数について1歩踏み込む- Link: Last access 2020/07/15.
- RDocumentation cor.test. Link: Last access 2022/05/16.
コメント欄
サーバー移転のため、コメント欄は一時閉鎖中です。サイドバーから「管理人への質問」へどうぞ。