Smirnov-Grubbs の外れ値の検定
UB3/statistics/outlier/smirnov_grubbs
このページの最終更新日: 2026/07/11広告
検定の手順
Smirnov-Grubbs test (単に Grubbs test という場合もある)は、データが 正規分布 に従うとき、含まれる外れ値を検出する方法である (1, 3)。
帰無仮説: 全てのデータは同じ母集団からのものである。
対立仮説: データのうち、最大のものは外れ値である。
- 標本の大きさを n、データを X1, X2, ...., Xn とする。
- 平均値を Xm、不偏分散を U とする。
- 最大または最小となる測定値 Xi について、次の式から統計量 Ti を求める。
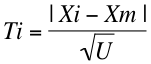
- 統計数値表から、有意点 t を求める。
R を使った検定
R の outliers という パッケージ を使って Grubbs test を行うことができる。
実行方法は、単に grubbs.test(vector) でよい。1 - 9 と 100 を要素としてもつデータセット x を作って Grubbs' test を行ってみる。
x=c(1,2,3,4,5,6,7,8,9,100)
grubbs.test(x)
結果は以下のようになり、100 が外れ値であることがわかる。。
data: x
G = 2.8356, U = 0.0073, p-value = 3.964e-09
alternative hypothesis: highest value 100 is an outlier
注意事項
データフレームの作成の際に、エクセルからのコピーをしたりすると、データが
> x=read.table(pipe("pbpaste"))
> x
V1
1 1
2 2
3 3
4 4
5 5
6 100
のように縦に並んだ形式になる。V1 は、列のラベルを指定していないときに勝手に定められるラベルである。ここで grubbs.test(x) としても、Error in `[.data.frame`(x, complete.cases(x)) :undefined columns selected というエラーになる。これはベクターでなくデータフレームを input にしてしまっているというエラーなので、$ を使って grubbs.test(x$V1) のように V1 行を指定すれば計算されるようになる。
広告
References
- スミルノフ・グラブス検定 http://aoki2.si.gunma-u.ac.jp/lecture/Grubbs/Grubbs.html
- Rで外れ値を計算する方法 Web.
- バイオスタティスティクス 外れ値 Web.
コメント欄
サーバー移転のため、コメント欄は一時閉鎖中です。サイドバーから「管理人への質問」へどうぞ。