Python: sklearn パッケージを使ったランダムフォレスト
UB3/informatics/python/rf_sklearn
このページの最終更新日: 2026/04/09- ランダムフォレストとは
- RandomForestClassifier: 目的変数が二値変数の場合
- ROC-AUC の算出
このページは、目的変数が二値変数の場合に使われる RandomForestClassifier についてのページです。目的変数が連続変数の場合は、RandomForestRegressor のページ を参考にしてください。
広告
概要: ランダムフォレストとは
ランダムフォレストの考え方は 回帰分析 と似ている。つまり、説明変数 x と目的変数 y があり、x から y を予測することが目的である。
ランダムフォレストは機械学習なので、トレーニングデータからモデルを作り、そのモデルを使ってデータから y を予測することになる。
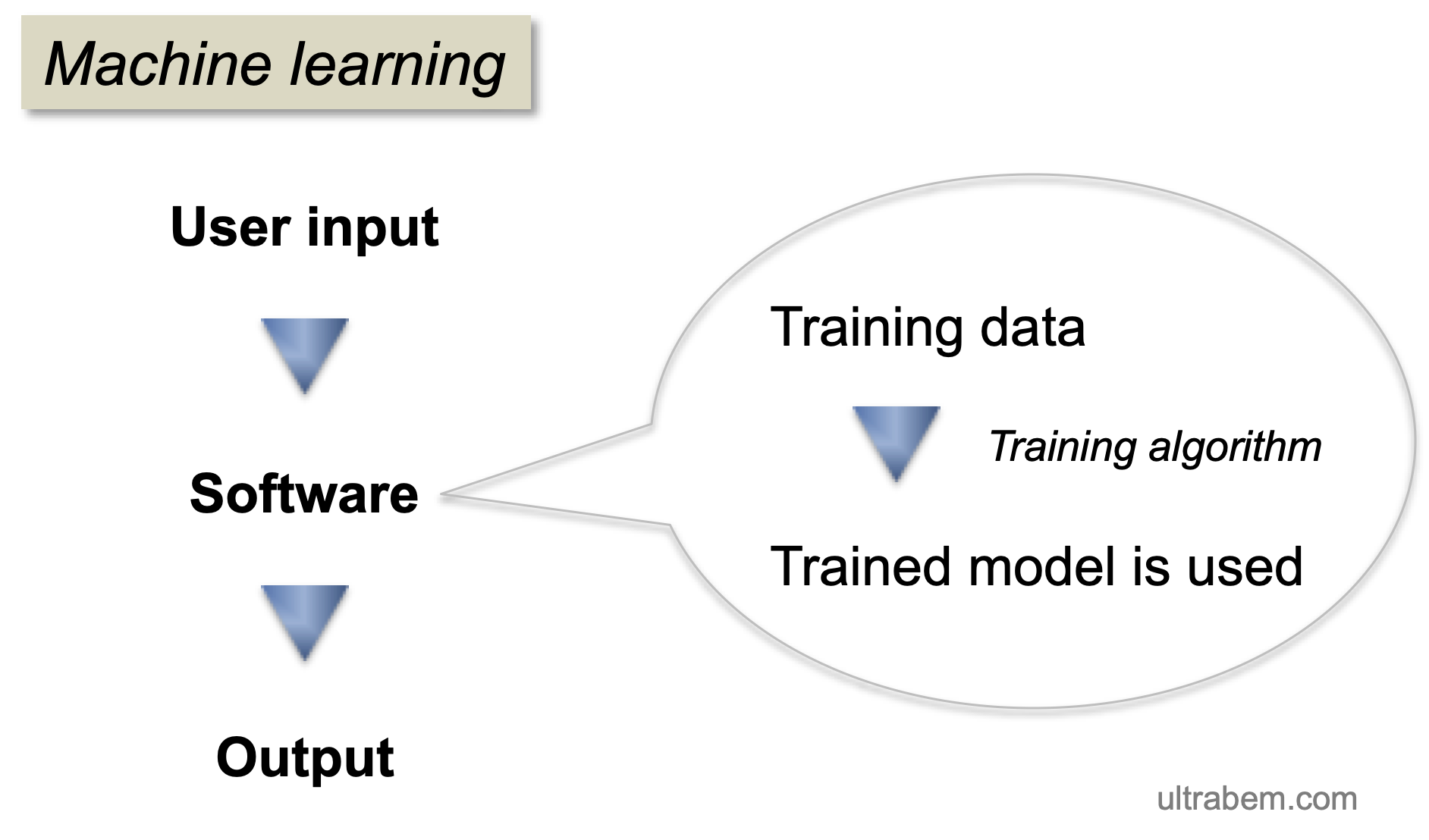
このページでは、Python の sklearn というパッケージに含まれる RandomForestClassifier についてまとめる。
RandomForestClassifier: 目的変数が二値変数の場合
RandomForestClassifier は、
たとえば、研究の対象者が 1,000 人いたとして、それぞれに病気である (y = 1) または病気でない (y = 0) という値が割り振られている。この 0 or 1 の二値変数が目的変数 y となる。
説明変数には、さまざまな変数を用いることができる。身長、体重などの連続変数、男女、気温、薄着で外出したかどうかなど、多くの変数が考えられる。
これらの説明変数を使ってモデルを構築すると、たとえば「気温が 10°C のときに薄着で外出した男性は病気になりやすい」というようなことがわかってくる。
このモデルに、別のコホートの説明変数を入れると、病気にかかるか否かを予測できるわけである。
実例 1
このページ を参考に、2022 年 12 月に実行した。コードなどは必要に応じて独自のものに変更してあるので、必要に応じてリンク先のページも参照のこと。
まず、必要なライブラリを読み込む。
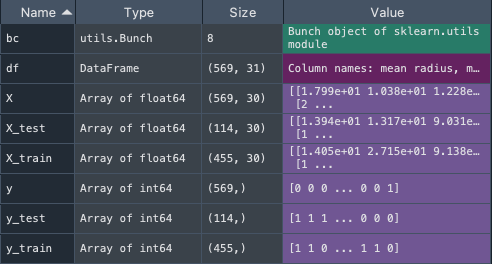
Python: Pandas のデータフレームから特定の行・列を抽出する のページでも用いた breast cancer というデータセットを使用する。
bc は Bunch object of sklearn.utils module というデータになり、pd.DataFrame を使わないと DataFrame にならない。
df はこのようなデータフレームになる。通し番号の Index と、mean radius, mean texture... などのデータが含まれている。569 行 30 列のデータである。
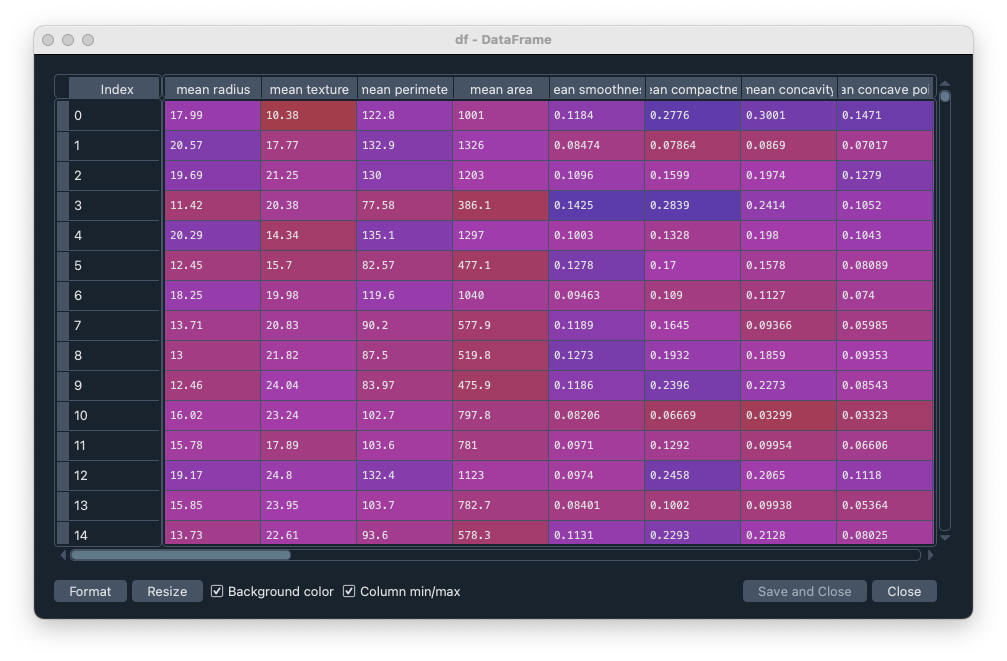
ここに、目的変数を追加する。これは一番右側に追加される 0 or 1 の列で、おそらくもともと bc に含まれているもの。これで df は 569 x 31 のデータになる。
目的変数 y と説明変数 X を設定する。1 行目は「target 以外」を意味する。
トレーニングデータとテスト用データに分割する。テストデータを 0.2 と設定してあるので、569 x 0.2 で 114 個が X_test と y_test に割り振られる。
モデルを学習させる。2 行目が実際の学習ステップで、単に model.fit に説明変数と目的変数を入れるだけでよい。model という変数が現れる。
学習モデルを使って予測する。X_test を入れて、y_pred がアウトプットになる。y_pred は、X_test から予測された値であり、0 or 1 のデータになる。個数は、もちろん X_test と同じ 114 個のデータになり、114 人の患者に相当する。
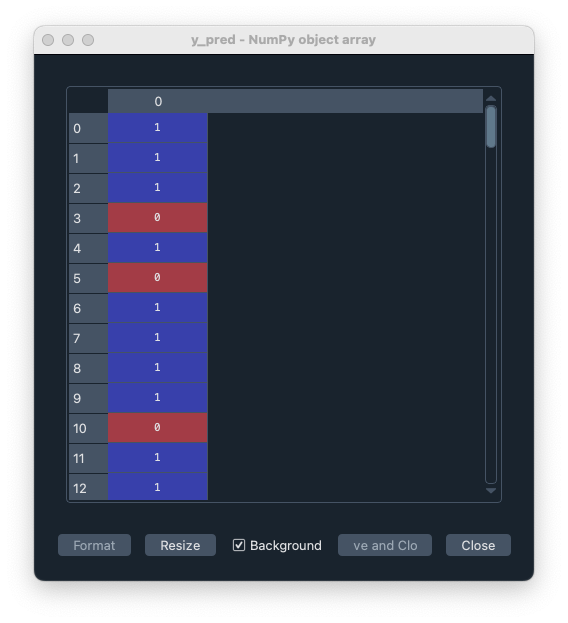
この y_pred は 0 or 1 で与えられているが、実際には「0 である確率」「1 である確率」を含むデータであり、これらの確率に一定の基準を設けて (1 である確率が 0.5 以上なら 1 とする、など) 0 or 1 のデータに変換している。
もとの確率データを見てみよう。
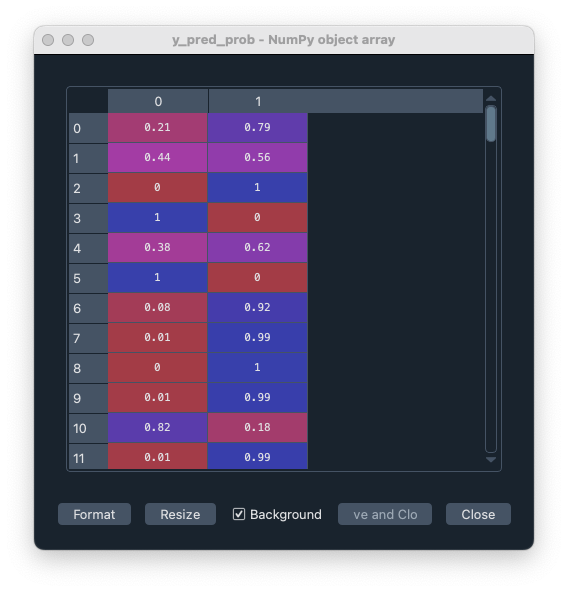
ここからは答え合わせ (モデルの評価) である。まずは
これは、単純に正答率が 0.8 などの数字で計算される。
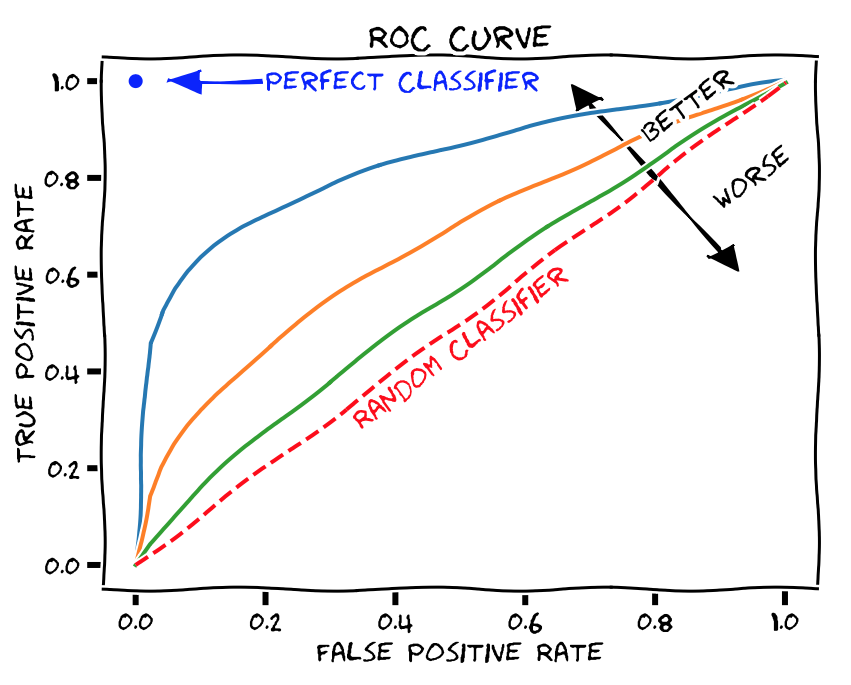
AUC という指標がある。これは ページの下の方で解説している ように、偽陽性や偽陰性の割合を振ったときのカーブから計算される値なので、0 or 1 の y_pred でなく、y_pred_prob を入れる必要がある。
ただ、なぜ 1 の予測確率を入れる ([:,1] を加えている) のか、よくわからない。わかったら更新。
広告
「あとがき」で当サイトを参考にしたと書いてくれているラノベです。Kindle Unlimited で読めました。ストーリーと文章が良く、面白かったです。
ROC-AUC の算出
ROC は、モデルを評価する指標の一つである。
モデルによって、それぞれの被験者に対する予測 (上の例なら病気であるか否か) が y = 1 または y = 0 で与えられる。実際に、被験者は病気であるか否かのどちらかなので、予測の正しさは以下の 4 パターンとなる。
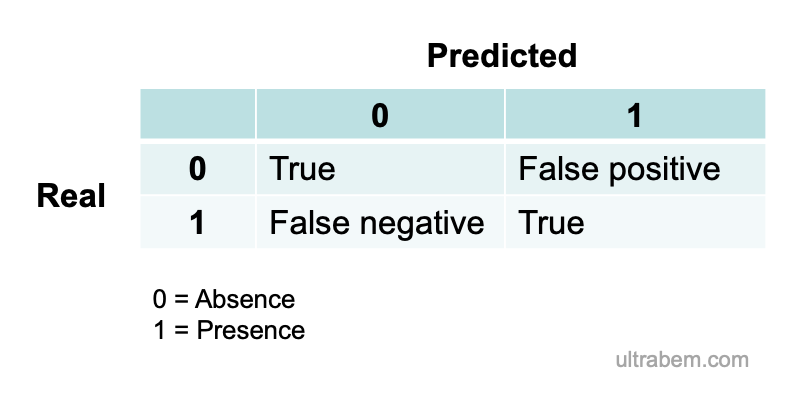
つまり、本当は病気でない (y = 0) のに 1 と予測してしまったら false positive, その逆は false negative である。(この先、あとで更新予定)
roc_auc_score(y_true, y_predicted) とする。y_predicted は予測値。
ここで、y_true は 01 正解ラベル。一つ一つのデータに対して付与される正解 (Ground Truth を示す情報のこと。教師あり学習や半教師あり学習で用いられる (参考)。つまり、AUC は目的変数が 0 or 1 でないと算出できない。
AUC の値の目安として、文献 4 には AUC = 0.7 - 0.8 が acceptable、0.8 - 0.9 は excellent、0.9 以上はoutstanding と書かれている。
広告
References
- Scikit-learnの使い方を徹底解説!AIエンジニアにおすすめ. Link: Last access 2022/11/18.
- 未来の数値を予測する!?AIの回帰分析を徹底解説! Link: Last access 2022/11/25.
- 第11回 機械学習の評価関数(二値分類/多クラス分類用)を理解しよう. Link: Last access 2022/12/14.
Mandrekar, 2010a. Receiver operating characteristic curve in diagnostic test assessment. J Thoracic Oncol 5, 1315-1316.
コメント欄
サーバー移転のため、コメント欄は一時閉鎖中です。サイドバーから「管理人への質問」へどうぞ。