Python: sklearn の RandomForestRegressor
UB3/informatics/python/rf_sklearn_reg
このページの最終更新日: 2026/04/09- RandomForestRegressor: 目的変数が連続変数の場合
広告
RandomForestRegressor: 目的変数が連続変数の場合
このページでは、Python の sklearn というパッケージに含まれる RandomForestRegressor についてまとめる。同じパッケージに含まれる RandomForestClassifier についてのページ もあり、そちらの方がランダムフォレストについての詳しい説明がある。
実例 1: California Housing データセット
まず、必要なライブラリを読み込む。ここは classifier と似ているが、classifier の評価項目である AUC、accuracy score などの読み込みは不要。
sklearn パッケージに含まれる California Housing データセットをインポートする。RandomForestRegressor もここで読み込んでおこう。
広告
「あとがき」で当サイトを参考にしたと書いてくれているラノベです。Kindle Unlimited で読めました。ストーリーと文章が良く、面白かったです。
データセットを読み込んで、学習データとテストデータに分割する。
このようにデータセットが分割される。70% が学習に使われる設定。
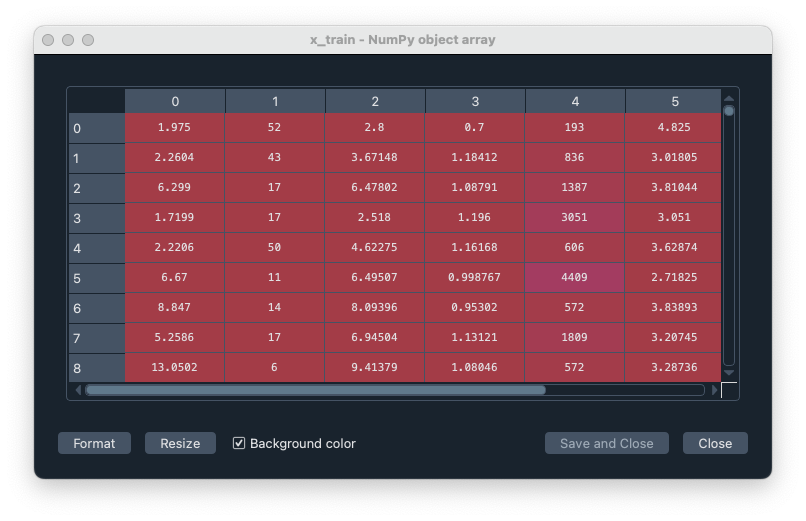
X_train は説明変数のデータセット。
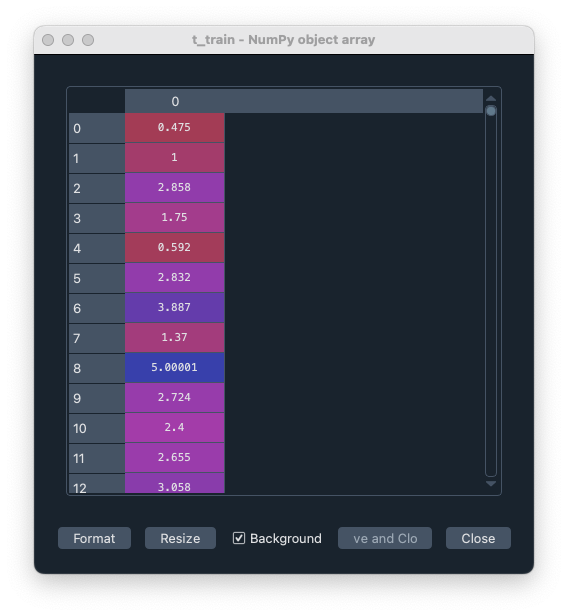
y_train は目的変数のデータセット。それぞれのデータ (それぞれの行) に対して 1 つの値であり、classifier とは違って連続変数である。
学習のステップ。random_state=0 は、結果が毎回変わるのを防ぐために必要。完了すると model という変数が現れる。
評価は「モデルスコア」というもので行うらしい。
回帰の場合は、スコア 0.5 ぐらいが目安らしい。このモデルでは 0.79 で、これはかなり良いスコア。
広告
References
- Scikit-learnの使い方を徹底解説!AIエンジニアにおすすめ. Link: Last access 2022/11/18.
- 未来の数値を予測する!?AIの回帰分析を徹底解説! Link: Last access 2022/11/25.
- 第11回 機械学習の評価関数(二値分類/多クラス分類用)を理解しよう. Link: Last access 2022/12/14.
コメント欄
サーバー移転のため、コメント欄は一時閉鎖中です。サイドバーから「管理人への質問」へどうぞ。