次世代シークエンシング:
データベースの見方、ダウンロード方法
UB3/informatics/bioinformatics/ngs_sra
このページの最終更新日: 2026/07/11- NCBI の NGS データベース
- SRA データベース
- SRA からデータをダウンロードする
- fastq ファイルのパラメーター
広告
概要: NCBI の NGS データベース
NCBI にある次世代シーケンス (NGS) のデータは、少なくとも以下のように分類されている。いずれも PubMed から検索することができる。
- Sequence Read Archive (SRA) には、アセンブル前のリードが登録されている。このページでは、主に SRA データベースの使い方を解説している。
- アセンブルされた配列が欲しい場合には、Assembly というデータベースがある。ここから assemble 済みの配列をダウンロードしたり、それに対して BLAST したりできる。
SRA データベースの項目
2015 年の このブログ (1) の記述から少しアップデートされているように思う。
「日本人のデータを探す」という実例を見てみるのがわかりやすいだろう。DDBJ のわかりやすい解説ページ も役に立つ。
Study |
論文情報など。All experiments, All runs などという項目へのリンクもあり、メタデータ的な性格をもつ項目。 |
Sample |
サンプル情報。単一の生物の場合や、メタゲノムの場合などいろいろ。 |
Library |
シーケンサーの種類、genome または transcriptome の別、ライブラリー構築のプロトコールなど。 |
Experiment attributes |
GEO Accession 番号が載っている。 |
Runs |
それぞれの Run ごとに固有のページがあり、そこへのリンクと簡単なサマリーが載っている。 |
実例1: 日本人のデータを探す
実例として、日本人の NGC データを探す方法を書いておく。
- PubMed のドロップダウンメニューを SRA にし、Japanese というキーワードで検索。9,500 件ほどのデータがヒットする (2018 年 2 月時点)。
- ページ右側に Top Organisms という項目がある。これを見ると腸内細菌叢のデータも混じっていることがわかるので、Homo sapiens をクリック。これでヒトの配列のみになる。
- Illumina Genome Analyzer など、様々なデータが一覧で表示されるはずである。塩基数、データサイズ、Accession などの情報は、この一覧ページでも見ることができる。

Whole genome resequencing of Masaru Tomita というデータに興味をひかれる。情報科学分野から生命科学に転向したメタボローム分野のパイオニア。実名でゲノム配列を登録するなど、さすがにやることが違う。
- データの一つをクリックすると、詳細な画面に移動できる。「日本人のデータ」ということを確認したい場合は、Runs の番号をクリックする。各データに 1 つの Accession 番号があり、その中に複数の Run データが番号つきで格納されているという構造になっているようだ。
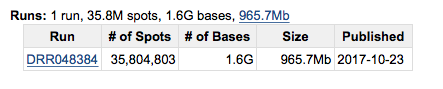
このように、1 つのデータに 1 Run しか含まれていない場合は、データのサンプル提供者 = Run のサンプル提供者ということになる。以下の 5 をするかわりに、この画面から直接 Sample をクリックしても良い。
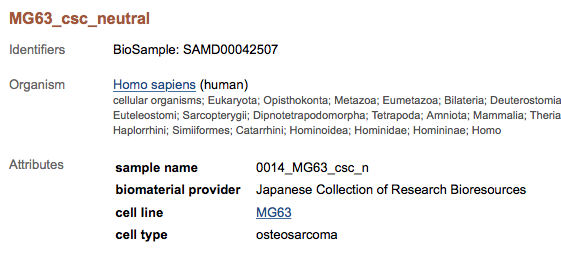
- Run の番号をクリックしたページに、Biosample という項目があり、ここにサンプル提供者の情報が載っている。リンクをクリックして、サンプル提供者のページへ。
- 下のように、biomaterial provider が日本人であることを確認できる。細胞の種類などもここに書かれている。
広告
「あとがき」で当サイトを参考にしたと書いてくれているラノベです。Kindle Unlimited で読めました。ストーリーと文章が良く、面白かったです。
SRA からデータをダウンロードする
NGS データのダウンロードには、コマンドラインの知識が必要となる。
Mac の Terminal、Linux の Terminal、または Windows の Command Prompt を使うことになる。
どの OS の場合も、ダウンロードに使うのは
データの番号を使って、以下のように実行する。
これで、上記の日本人データ DRR048384 がダウンロードされる。私の場合はホームフォルダにダウンロードされた。処理が終わると、ターミナルに再びコマンドを入力できる状態になる。
ダウンロードした fastq ファイルは、アダプターの除去、低品質な配列の除去などのクリーンアップは終了していることが多い。詳細については fastq ファイルのクリーンアップ を参照のこと。
広告
References
ページ分割のため本文中に引用されていないものがありますが、番号と本文は対応しています。
- yokaのblog. 次世代シーケンスデータベース (SRA) の見かた. Link: Last access 2018/02/05.
- https://www.illumina.com/documents/products/technotes/technote_Q-Scores.pdf
コメント欄
サーバー移転のため、コメント欄は一時閉鎖中です。サイドバーから「管理人への質問」へどうぞ。