R: 欠損値 NA の取り扱い
UB3/informatics/r/na
このページの最終更新日: 2026/04/09広告
概要: R 欠損値 NA とは
R には NA, Inf, NULL などの数値でない値がある。このページでは、NA とその取り扱いについてまとめる。
いくつかメモ。
- NA は数でないので、イコールなどの概念は成り立たない。たとえば 1 == 1 とすると TRUE となるが、NA == NA だと NA という答えが返ってくる。ある値が NA であるかどうかは、== ではなく is.na () 関数を使って調べる。
- 同じ大きさのデータフレーム A, B があり、A に NA があるとき、C = A + B とすると、A の NA の位置に NA が入る。他の位置は足し算になる。これを使って「A が NA なら B も NA」を実行できそう。
- 参考: 欠損データの処理 は良いページ。
NA に関連する関数
is.na() |
欠損値 NA かどうか。このほか、is.null(), is.nan(), is.finite(), is.infinite() などがあり、同様の使い方ができる。 応用の範囲が非常に広い。
|
na.omit() |
データフレームに対して使用する (1)。NA が一つでも含まれる行を取り除く。Na が一つでも含まれる列を取り除く場合は、apply() 関数を使用して、以下のようにする。 df_clean <- df[, !apply(df, 2, function(x) any(is.na(x)))] |
na.rm |
関数でなく、一部の関数に含まれるオプション。例えば sum 関数で sum(A) とすると、A に NA が含まれる場合は合計が計算されず、結果も NA になってしまう。しかし、sum(A, na.rm = TRUE) とすると、NA を除いて合計を計算する。 |
広告
「あとがき」で当サイトを参考にしたと書いてくれているラノベです。Kindle Unlimited で読めました。ストーリーと文章が良く、面白かったです。
NA を 0 に置き換える
data というデータフレーム中で、ある特定の数 N をゼロに置き換えるときは以下のようにする。[data == N] の中は、TRUE または FALSE が並んでいることになる。
NA は数でないので == は使えないが、TRUE または FALSE を並べればよいわけで、かわりに is.na が使える。つまり
となる。
NA を使って全て非有意のデータを除く
P < 0.05 などの基準を決めて、その値を全て NA にする方法。
まずデータの準備をする。p value のデータフレーム A と、データのデータフレーム B がある状態を作ってみる。
a2 = abs(rnorm(n=100, m=0.03, sd=0.02))
b1 = abs(rnorm(n=100, m=20, sd=5))
b2 = abs(rnorm(n=100, m=20, sd=5))
A = data.frame(data1_pval = a1, data2_pval = a2)
B = data.frame(data1 = b1, data2 = b2)
これで A, B が以下のように作成される。一部のデータしか示していないが、2 x 100 のデータフレームである。
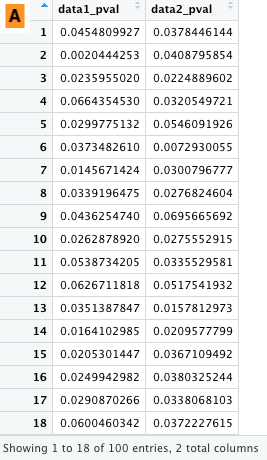
|
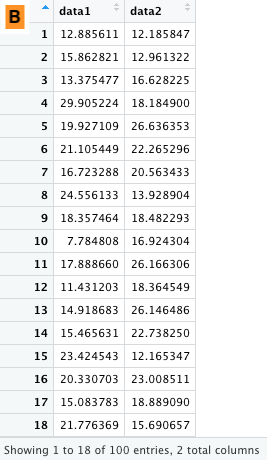
|
A が p 値で、a1 のヒストグラムは以下のようになっている。大雑把に、3 分の 1 か 4 分の 1 ぐらいが P > 0.05 に見える。
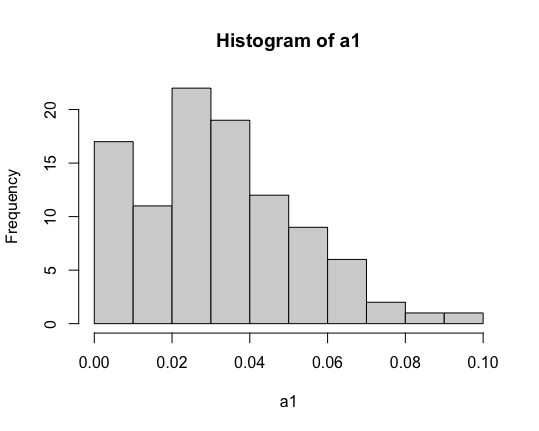
A_NA という変数を作り、0.05 以上の値に NA を代入する。
A_NA[A_NA >= 0.05] <- NA
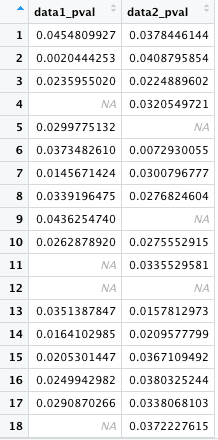
試しに A_NA に is.na 関数を使ってみると、TRUE または FALSE が返される。
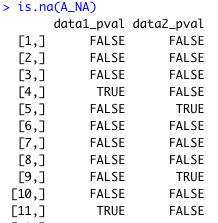
これを使って、「A が NA ならば B も NA」としたい。A と B を別々のデータフレームとして扱ってきたが、一つにした方が見やすいようである。A_NA と B を結合して C にする。データフレームの取り扱い も参照のこと。
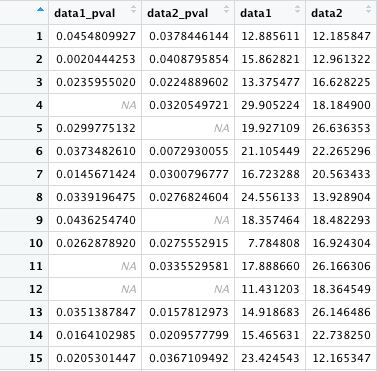
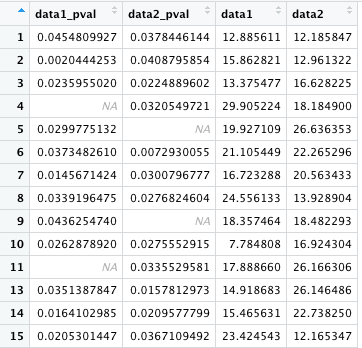
このデータフレームに対して、いくつかのパターンで NA を用いた置換をしてみる。
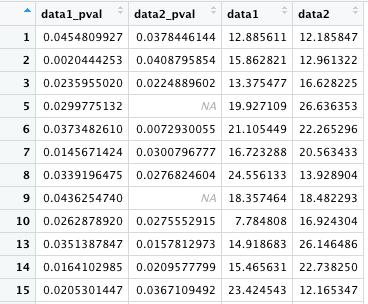
まず、! は is.na の逆をとるという意味なので、以下は is.na が FALSE であるものが D に保存される。つまり、data1_pval が NA のものが除かれる。行の 4, 11, 12 が除かれている。
最後のコンマは、行方向にこれを行うという意味。これがないとエラーになる。
is.na は TRUE または FALSE を返すので、D = C[is.na(C) == FALSE,] としても同じ結果になる。コンマの位置が少しわかりにくいが、これは FALSE でなく条件式全体にかかっている。
! を除くと、is.na が TRUE であるものが E に保存される。D = C[is.na(C) == TRUE,] としても同じである。
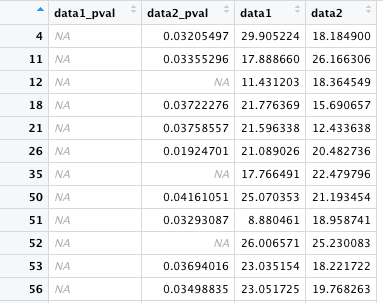
この 2 つは同じ意味である。& は「A かつ B」の演算子なので、data1_pval と data2_pval が両方とも NA でない行を選択することになる。
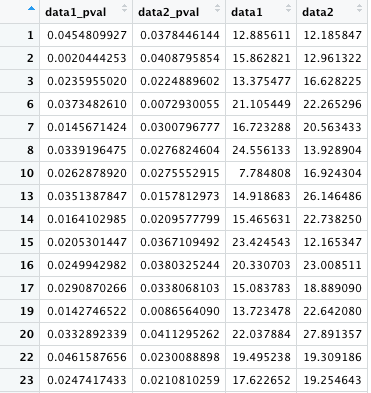
同じように、data1_pval と data2_pval が両方とも NA である行を選択する場合。
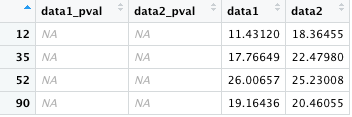
& の代わりに or 演算子 | を使うと、「data1_pval または data2_pval が NA である行」を選択できる。
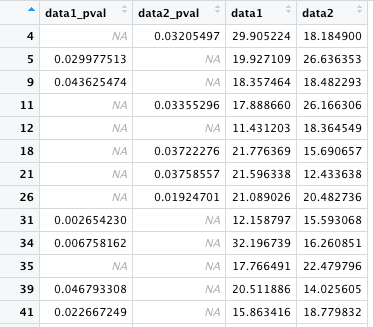
data1_pval または data2_pval に NA でないものが含まれていれば OK という書き方。つまり、G の両方 NA のものだけが除外されることになる。
最後になってしまったが、見出しの
広告
References
- 欠損値. Link: Last access 2022/05/17.
- How to Use is.na in R with examples. Link: Last access 2022/05/18.
コメント欄
サーバー移転のため、コメント欄は一時閉鎖中です。サイドバーから「管理人への質問」へどうぞ。