R: ヒートマップから特定のクラスターを取り出す
UB3/informatics/r/heatmap_cluster_extract
このページの最終更新日: 2026/07/11広告
概要: ヒートマップの特定のクラスターを取り出す
下にあるような、値を色の違いで表した図をヒートマップ heatmap という (図は Public domain)。ヒートマップを作る際には、データを並べ替えるクラスタリング clustering も同時に行われることが多い。下の図では、X および Y の 2 つの軸でクラスタリングが行われている。
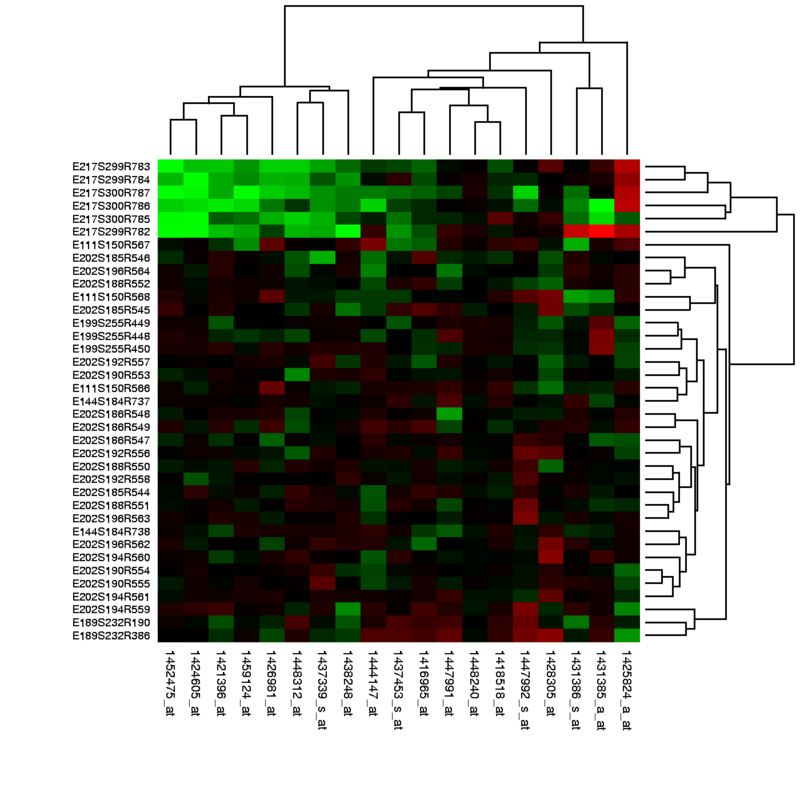
研究の過程で、ヒートマップを作成した後に特定のクラスターを取り出したいケースがあった。データ数が少なければ手動でできるのだが、非常に多くて行の文字が見えないような状態だったので、R を使って取り出す必要があった。そのときのメモ。
広告
「あとがき」で当サイトを参考にしたと書いてくれているラノベです。Kindle Unlimited で読めました。ストーリーと文章が良く、面白かったです。
heatmap.2 関数
あまりネットに情報がないが、役に立ったのは このページ。heatmap.2 を使うが、クラスター解析には hclust という別の関数を使う。hclust の結果を row_clust という変数に保存して、それを使って heatmap.2 でヒートマップを書き、また row_clust から直接クラスターを取り出している。
mat というのがデータを含む行列で、スクリプトはこんな感じ。heatmap.2 を使っているので、gplots ライブラリが必要。
# まず変数を row_clust として保存。
# クラスタリングに row_clust を as.dendrogram で使用している。
これとは別に、plot で直接 dendrogram を作成。クラスターの指定は、cutree を使って k でクラスターの数を指定する。
または、h でカットオフ値を指定する。こっちの方が、abline でカットオフの場所を視覚化できるので好みである。
abline(h = 70, col = "red2", lty = 2, lwd = 2)
table を使って、各クラスターに含まれる要素の数を見ることができる。
ComplexHeatmap 関数
column_order, row_order を使う。普通に実行すると警告が出るので、以下のような形をとっている。
警告: The heatmap has not been initialized. You might have different results if you repeatedly execute this function, e.g. when row_km/column_km was set. It is more suggested to do as `ht = draw(ht); column_order(ht)`.
column_order, row_order にヒートマップ h1 を入れると、以下のように番号が出力される。

このヒートマップは以下のようになっている。つまり、column は 3 つのクラスターに分かれており、クラスター 1 が一番大きく、2 と 3 には 1 個ずつのデータしか含まれない。上の数字で、クラスターは [[1]] などのように表されている。
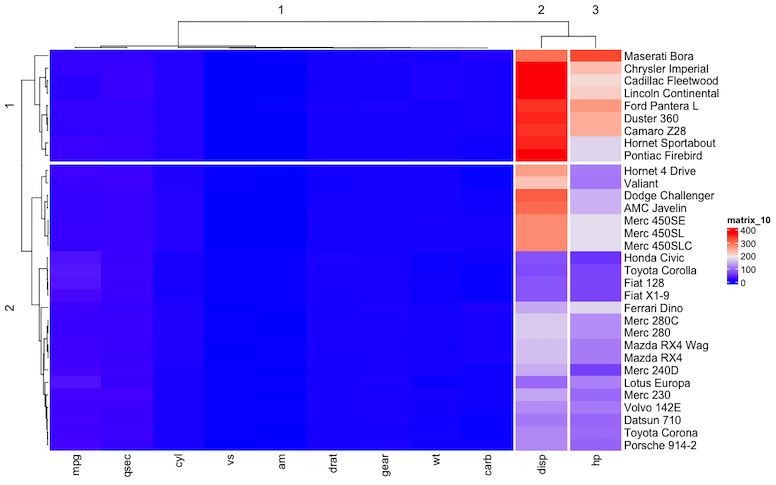
[[1]] の要素として並んでいる 1 7 2 8... などの数字は、もとの mtcars データを参照する。
ここの列番号が使われている。1 = mpg, 7 = qsec, 2 = cyl... のように、もとの列番号でデータを指定し、それがヒートマップに現れる順番で示されている。
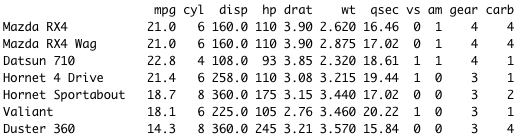
ここまでわかれば、クラスターの抽出が可能だろう。たとえば右の赤い 2 列を取り出したい場合、クラスターの 2 と 3 であり、これはもとの mtcars データの 3 および 4 列目にそれぞれ相当する。つまり mtcars[3], mtcars[4] となる。
手動でこのようにするには数が多い場合もあると思うので、もう少しこのデータを詳しく見てみよう。
table を使って、各クラスターに含まれる要素の数を見ることができる。
A[[1]]
[1] 1 7 2 8 9 5 10 6 11
column_order の結果を A というオブジェクトに格納すると、A はそれぞれのクラスターの行番号を要素としてもつリストになる。この場合、3 つの要素になる。
リストから要素を取り出す際は、データフレームのように $ を使うのではなく、二重鉤括弧を使い [[1]] のようにする。
もとデータ mtcars の列番号を、A[[1]] などを使って指定すればよい。列番号指定はmtcars[列番号] なので、鉤括弧が多くなるが
となる。ここからさらに 1 行目の Mazda RX4 を抽出したい場合は、
でよい。
広告
References
- Link: Last access 2022/07/15.
コメント欄
サーバー移転のため、コメント欄は一時閉鎖中です。サイドバーから「管理人への質問」へどうぞ。