人工知能 AI の概要:
機械学習との違い、各種アルゴリズム、用語集
UB3/informatics/ai/ai_overview
このページの最終更新日: 2026/07/11広告
概要: 人工知能 AI とは – 機械学習との違いなど
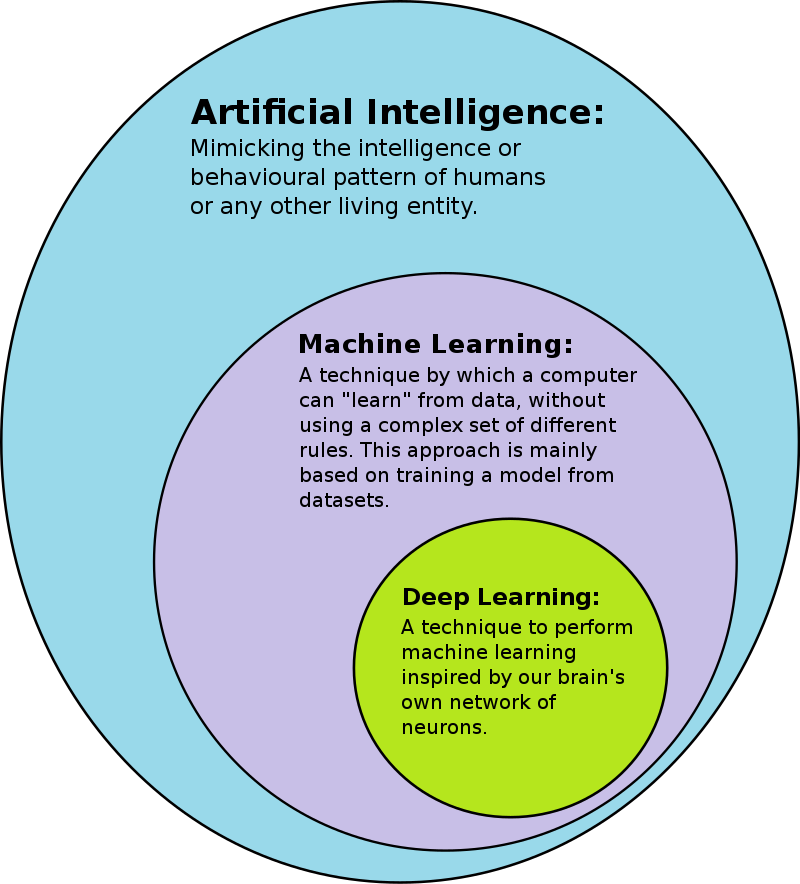
図 (文献 1) に示したように、
Deep learning, a recently introduced branch of machine learning, applies a system of artificial neural networks (ANNs) with several hidden layers that compute a transformation of the underlying data that result in an output layer associated with a class (2).
広告
「あとがき」で当サイトを参考にしたと書いてくれているラノベです。Kindle Unlimited で読めました。ストーリーと文章が良く、面白かったです。
機械学習 Machine learning
機械学習とは、上で述べた通り「経験やデータを通じてコンピューターが学習し、特定のタスクを実行できるようになる」プロセスをいう。これについてもう少し考えてみる。
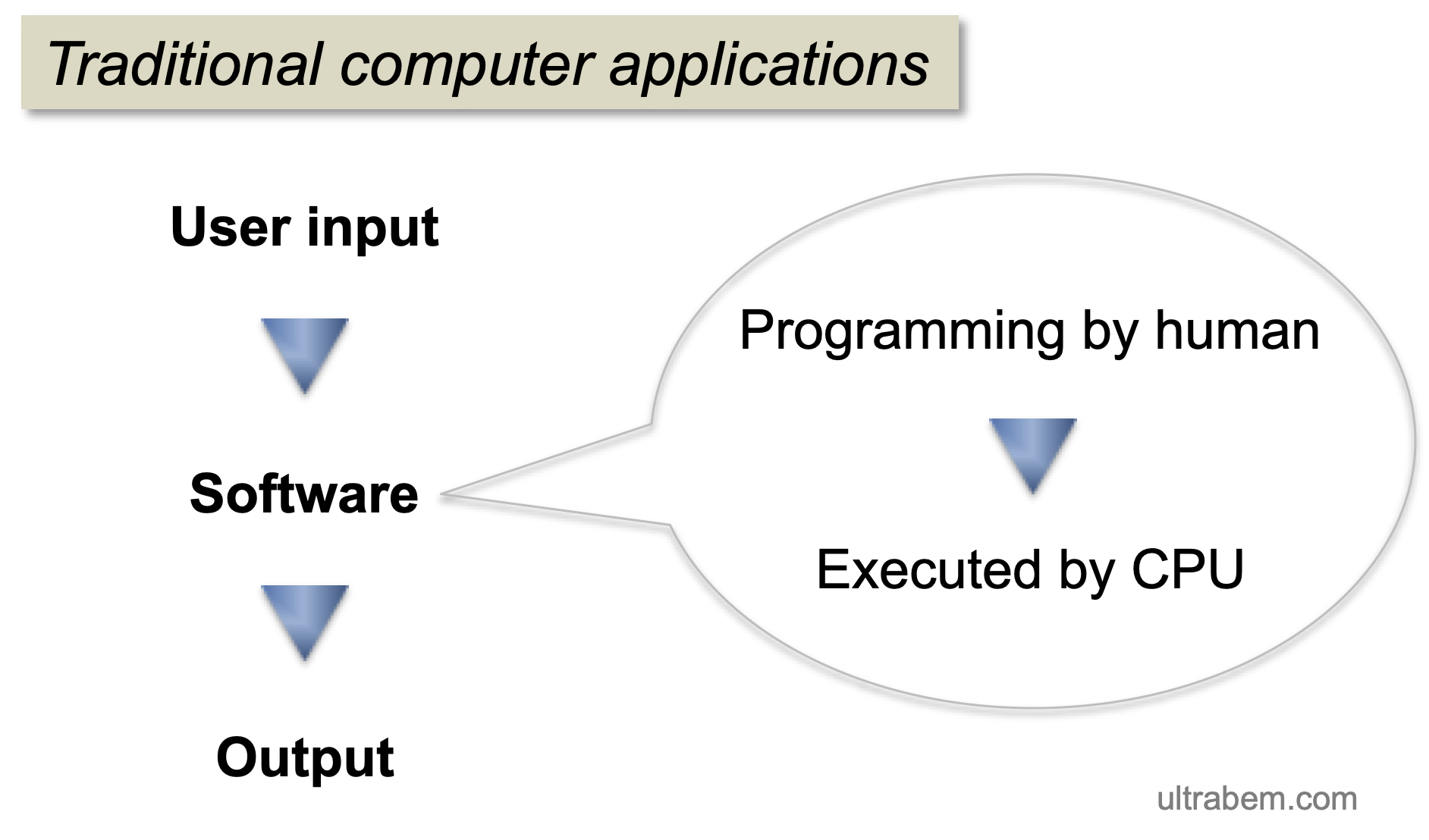
従来のコンピューターというのは、基本的にはプログラムされた通りに動くものである。たとえばユーザーが何かを入力した場合、その入力値をどう扱うか、どういう状況ならどういうエラーが出るか・・・などの項目は、細かい場合分けをされたプログラムに全て書かれている (図、Public domain)。
この「人間によってデザインされたプログラム」に基づいてソフトウェアが入力値に対して処理を実行し、結果を output として返す。
これに対して、機械学習では、コンピューター自身が
人間のプログラムの代わりに、コンピューター自身が学習し、あるモデルを構築する。このモデルを使って、入力値に対する処理が実行されるわけである。人間は、モデルを構築するためのアルゴリズムを作成するだけである。
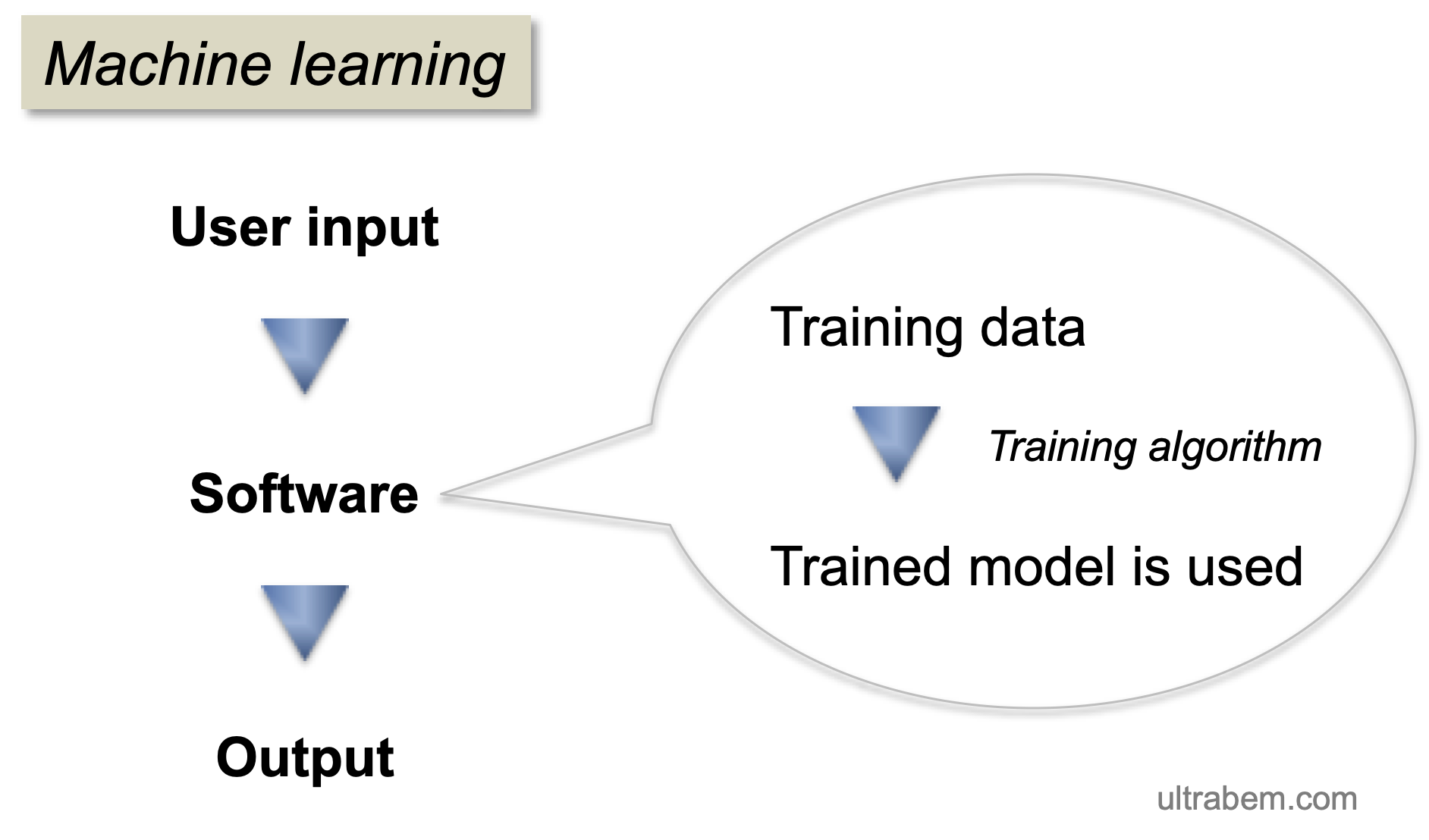
機械学習の input と output
いくつか機械学習の実例を挙げてみる。
画像認識・生成 |
新しい画像を生成、画像の分類、異常のある画像を検出、画像内の物体を検出、人間や動物の骨格を推定するなど、さらに詳細な分野がある。
|
二値分類 |
臨床研究でよく使われる。複数のデータから、患者が特定の疾患をもっているかどうかを 0 or 1 で判断する。 |
教師あり学習と教師なし学習
上で述べたように、機械学習には「学習してモデルを作り出すステップ」が必要になる。これは大きく
機械学習 用語集
機械学習に関係した用語を簡単に表にしておく。
K 近傍法 (RF) |
k-nearest neighbor algorithm, k-NN。しばしば「最も単純な ML アルゴリズム」と表現される。 |
K 点平均法 (RF) |
k-means 法。データを教師なしでクラスタリングする方法。まずデータを適当なクラスタに分け、クラスタの平均を用いてさらに調整していく。 k はクラスターの数になる。R ヒートマップ にある ComplexHeatmap という関数では、この方法でクラスタリングするオプションがある。 |
Support vector machine (SVM) |
サポートベクターマシン SVM は、supervised ML の一つである。1963 年に線形モデルが発表され、1992 年に非線形モデルに拡張された。 "unsupervised SVM" で検索してみると、数百件の論文がヒットする。おそらく、拡張アルゴリズムが日々作られている状況なので、それぞれのアルゴリズムに対して supervised と unsupervised の別、また線形と非線形の別を書くのはあまり意味がないと思われる。 |
Naive Bayes |
線形モデル。トレーニングデータが少なくて良いのが特徴らしい。 |
Gradient boosting decision tree (GBDT) |
非線形モデル。 |
Artificial neura network (ANN) |
単にニューラルネットワークと呼ばれることもある。脳にみられる特性に類似したモデル、非線形。 ネットワークを形成した各ノードが、学習によってシナプスの結合強度を変化させ、能力を向上させていくようなモデルの総称。 |
決定木 |
「けっていぎ」と読む。フローチャートを作成するようなものと理解している。詳細は 決定木のページ を参照のこと。 |
Random forest (RF) |
教師ありモデル。多数の決定木を使用するので、このような名前がついているらしい (図、Ref. 3)。 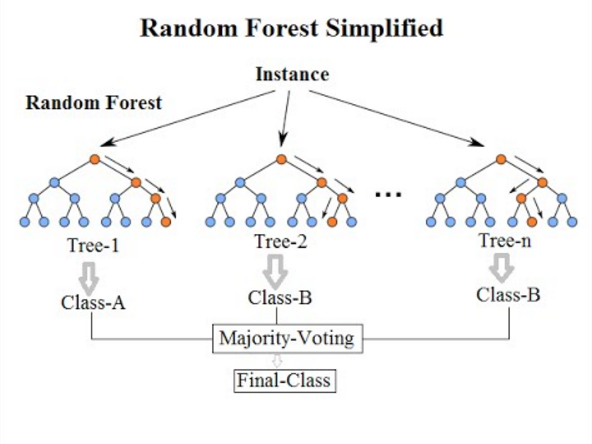
|
その他メモ
2022 年ごろから発展した ChatGPT などの生成型 AI について。 (参考)。
大規模言語モデル LMM という仕組みに基づく。ほとんどの LLM は、トランスフォーマーと呼ばれるアルゴリズムを使っている。これは、言語処理に適した工夫がされたニューラルネットワークの一種である。
基本アイディアは「単語同士の関連性」であり、「この単語の次に、どの単語が来やすいか」を膨大なデータから学習し、出力しているようだ。よって、出力される文章は「平均的なもの」になる。
Bard の学習ソースは、arXiv:2201.08239v3 によると以下のようになっている。Public form などが多く、12.5% が Wikipedia。英語以外のソースは 6.25% と少ない。
|
The pre-training data, called Infiniset, is a combination of dialog data from public dialog data and other public web documents. It consists of 2.97B documents and 1.12B dialogs with 13.39B utterances. The composition of the data is as follows: 50% dialogs data from public forums; 12.5% C4 data [11]; 12.5% code documents from sites related to programming like Q&A sites, tutorials, etc; 12.5% Wikipedia (English); 6.25% English web documents; and 6.25% Non-English web documents. The total number of words in the dataset is 1.56T. |
ChatGPT は、前にした質問を「覚えて」いる。どんな内容かを判断して、重要そうなものを覚える仕様になっている。設定から Personalization - Memory で、Manage Memory とすると、何がそのアカウントについて記録されているかを見ることができる。
管理人はアンチ生成 AI である。モノを考えない人間が増加し、それが「普通」になっていくと、絶望に近い感情を覚えている。ネット検索や動画についても同じような悲観論があったと思うが、生成 AI はその流れを加速し、決定的にするものではないかと考えている。寄稿記事 生成 AI の未来についての悲観的な見通し とほぼ同じ意見。
X で見渡しても、生成 AI に悲観的な研究者があまりいないのを不思議に思っていたが、東京大学教授 酒井邦嘉氏の 生成AIは教育に百害あって一利なし〜手書きで人間の創造性を という記事を見つけて、我が意を得たりという感じだった。著書を読んだこともある、認知分野をリードする研究者である。要点をメモしておく。
- 生成 AI は、まず一律に禁止してから使い方などを議論すべき。
- 「新しい技術にもオープンでなければならない」などと一見物分かりの良さそうな言い方をする場合があるが、ドーピング、毒ガス兵器など、使うべきでない技術はいくらでもある。パソコン、インターネットなどは、結果的にたまたま良かったケースである。
- 「これだけ既に広がっているから認めるべき」という議論も詭弁である。
- 電卓にも否定的だが、文章を書く力というのは思考能力の根源なので、生成 AI にはさらに深い危惧を抱いている。
大学教育について言えば、レポートによる評価というものが非常に難しくなっており、面談型でないと学生の実力を評価できないという状況になっている。これは教員の負担を著しく増加させ、さらにそうしたプレッシャーを伴う「教育」を好まない学生も増えてきている。生成 AI は、少なくとも大学教員という職の魅力を著しく引き下げたと言えるだろう。
ただし、生成 AI 批判でたまに使われる「既存のものを切り貼りしているだけで、新しいものを生み出していない。創造性はない。」というロジックは良くないと思う。人間が行う「創造」が脳内でどういうプロセスであるのかわからないが、たとえば「今までになかった 2 つのものの組合わせ」が創造なら、それは生成 AI でも可能である。問題点はやはり以下の 2 点であると考える。
- クリエイターの保護。著作権の観点から生成 AI を規制するように法制度を整えるべき。また、現状は「OpenAI などの営利企業が、個々のクリエイターに迷惑をかけながら利益を出している」状態である。 たとえば大企業から下請けを保護する下請法があるように、弱者保護の観点からの規制もあるべきだ。問題なのは、生成 AI が無料で使えたりしてしまうため、ほとんどの人間が強者の側に立っていること。「みんなで盗めば怖くない」状態で、そのためクリエイター保護の世論が盛り上がらないのではと思っている。
- 人間の知性に対する悪影響。麻薬と同等に扱って規制してもいいぐらいだ。
2024 年末から 2025 年にかけて、Journal of Human Evolution 誌のエディターが大量辞職した (参考)。エルゼビアがエディターに知らせることなく AI を編集に導入したため。
広告
References
- By Original file: <a href="//commons.wikimedia.org/w/index.php?title=User:Avimanyu786&action=edit&redlink=1" class="new" title="User:Avimanyu786 (page does not exist)">Avimanyu786</a>SVG version: <a href="//commons.wikimedia.org/wiki/User:Tukijaaliwa" title="User:Tukijaaliwa">Tukijaaliwa</a> - <a href="//commons.wikimedia.org/wiki/File:AI-ML-DL.png" title="File:AI-ML-DL.png">File:AI-ML-DL.png</a>, CC BY-SA 4.0, Link
Tran et al., 2019a. Personalized breast cancer treatments using artificial intelligence in radiomics and pathomics. J Med Im- Venkata Jagannath - https://community.tibco.com/wiki/random-forest-template-tibco-spotfirer-wiki-page, CC 表示-継承 4.0, https://commons.wikimedia.org/w/index.php?curid=68995764による
コメント欄
サーバー移転のため、コメント欄は一時閉鎖中です。サイドバーから「管理人への質問」へどうぞ。